YOLO, You Only Look Once
YOLO unifies object detection into a single convolutional neural network that processes the entire image in one forward pass.
- Original Paper: You Only Look Once: Unified, Real-Time Object Detection
- GitHub Repo: Deep Learning Classics: Read, Review, Recode
Abstract
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is less likely to predict false positives on background. Finally, YOLO learns very general representations of objects. It outperforms other detection methods, including DPM and R-CNN, when generalizing from natural images to other domains like artwork.
Background & Problematic
Humans glance at an image and instantly know what objects are in the image, where they are, and how they interact.
Current object detection systems often adapt classifiers for detection tasks. Traditional methods like Deformable Parts Models (DPM) use a sliding window approach to run the classifier across the whole image. Newer methods like R-CNN first generate region proposals (potential object locations), then classify each region. Post-processing follows to refine box positions, remove duplicates, and adjust scores based on context.
These complex pipelines are slow and hard to optimize because each individual component must be trained separately.
We reframe object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities (you only look once (YOLO) at an image to predict what objects are present and where they are.)
A single CNN simultaneously predicts multiple bounding boxes and class probabilities for those boxes. Benefits:
- YOLO is extremely fast (45 frames per second).
- YOLO reasons globally about the image when making predictions (implicitly encodes contextual information about classes and appearance).
- YOLO learns generalizable representations of objects.
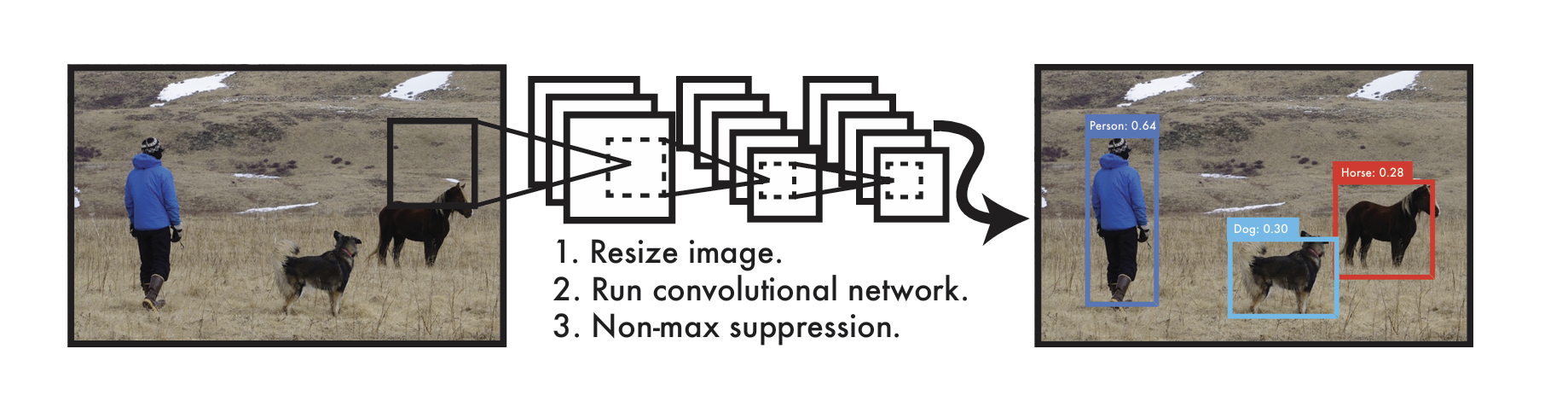 The YOLO Detection System.
The YOLO Detection System.
Core Idea: Unified Detection
YOLO unifies object detection into a single convolutional neural network that processes the entire image in one forward pass. It divides the input image into an $S \times S$ grid. If an object’s center falls within a grid cell, that cell is responsible for detecting it.
Each grid cell predicts:
$B$ bounding boxes, each with:
- Coordinates: $(x, y, w, h)$
Confidence score:
\[\text{Confidence} = \Pr(\text{Object}) \times \text{IOU}_{\text{truth, pred}}\]
$C$ conditional class probabilities, given that an object is present:
\[\Pr(\text{Class}_i \mid \text{Object})\]
Each bounding box thus makes 5 predictions: $(x, y, w, h, \text{Confidence})$
At test time, the class-specific confidence score for each box is computed as:
\[\Pr(\text{Class}_i) \times \text{IOU}_{\text{truth, pred}} = \Pr(\text{Class}_i \mid \text{Object}) \times \Pr(\text{Object}) \times \text{IOU}_{\text{truth, pred}}\]This final score reflects both the probability of the class and how well the predicted box matches the ground truth, enabling efficient and accurate object detection across the whole image.
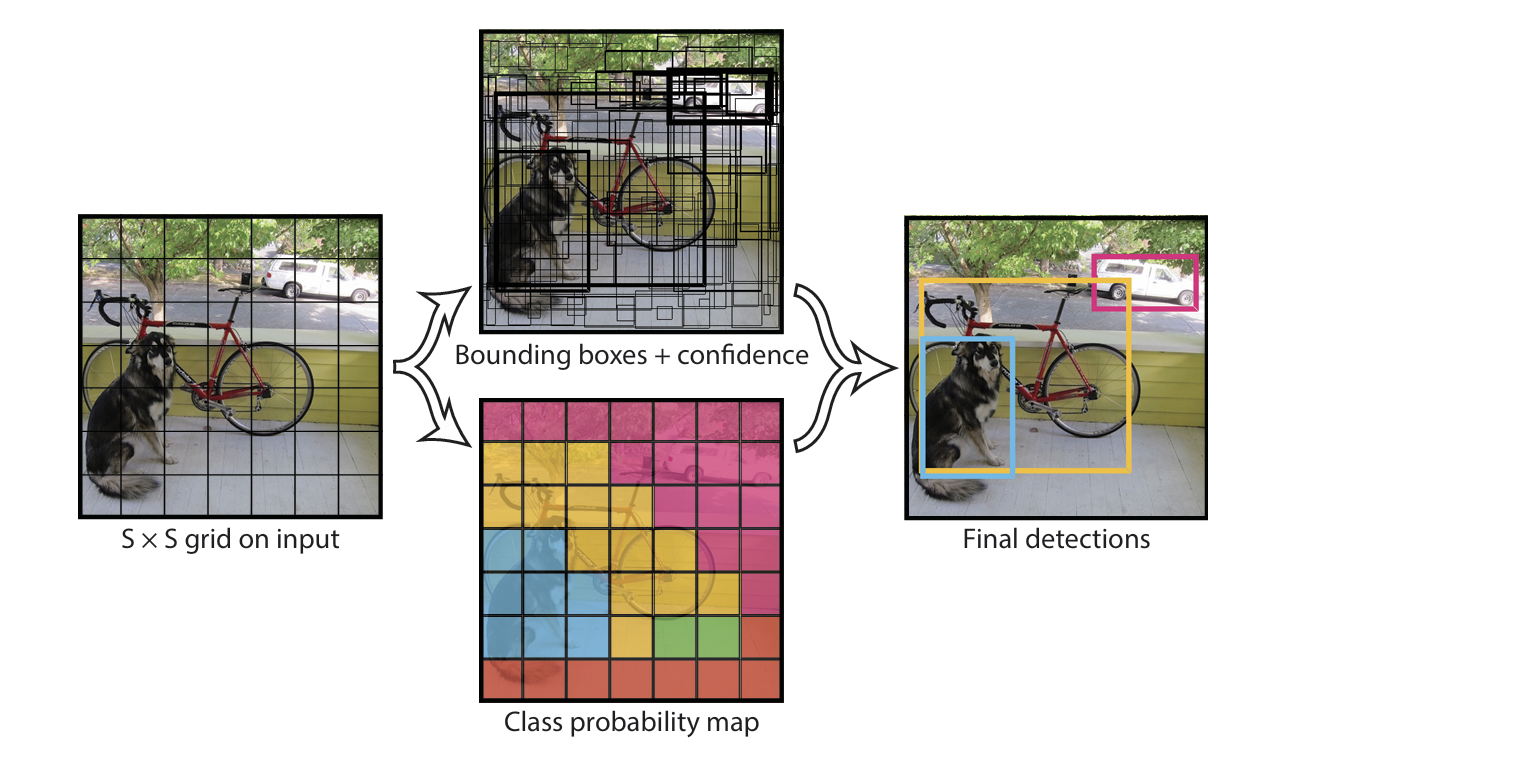 The Model. Predictions are encoded as an S*S (B*5+C)tensor.
The Model. Predictions are encoded as an S*S (B*5+C)tensor.
Network Design
The YOLO model is implemented as a convolutional neural network and evaluated on the PASCAL VOC dataset. The architecture consists of:
- 24 convolutional layers for feature extraction
- 2 fully connected layers for predicting bounding box coordinates and class probabilities
It is inspired by GoogLeNet but replaces inception modules with 1×1 reduction layers followed by 3×3 convolutions, similar to Lin et al.’s approach.
A faster variant, called Fast YOLO, reduces the number of convolutional layers to 9 and uses fewer filters, trading accuracy for speed.
The network outputs a 7×7×30 tensor, representing predictions over the image grid.
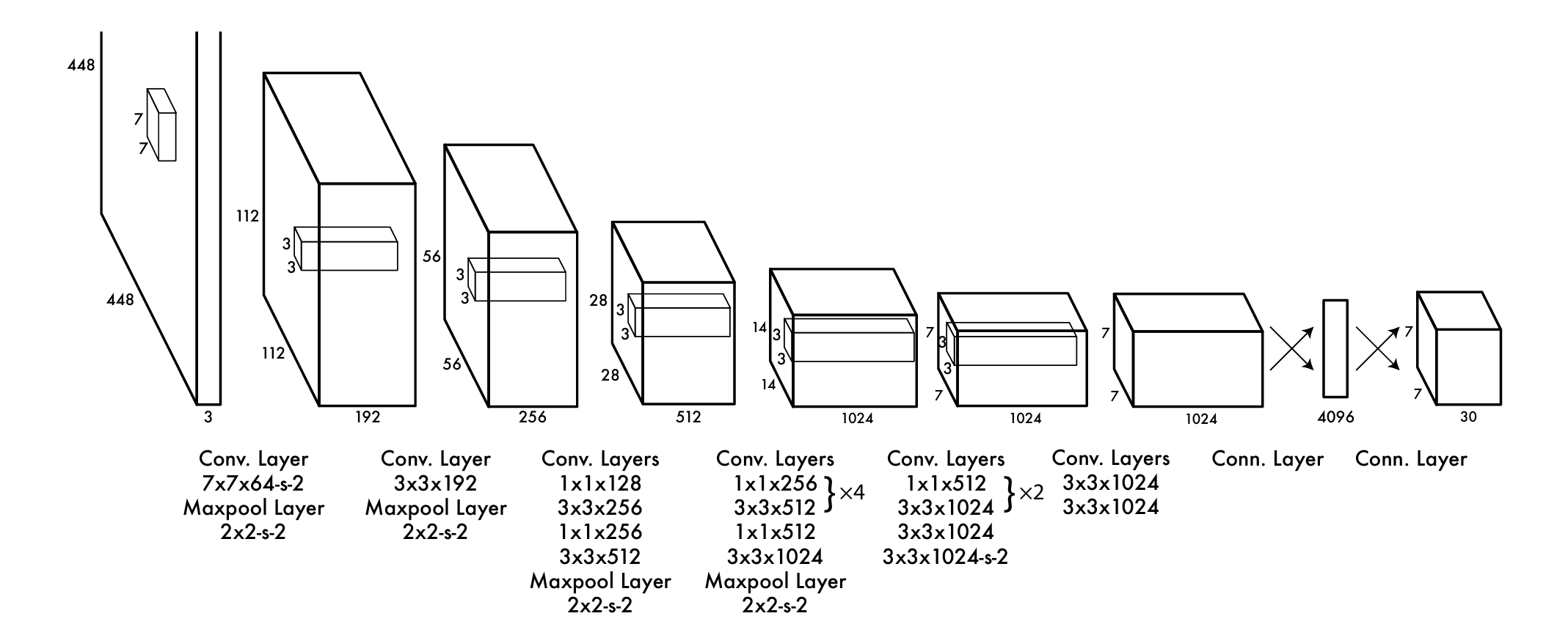 YOLO architecture
YOLO architecture
Training
- Pretraining:
- The first 20 convolutional layers are pretrained on the ImageNet 1000-class dataset using the Darknet framework.
- Achieves 88% top-5 accuracy on the ImageNet 2012 validation set.
- Conversion to Detection:
- Added 4 convolutional layers and 2 fully connected layers (randomly initialized).
- Input resolution is increased from 224×224 to 448×448 for finer spatial detail.
- Final Output:
- A 7×7×30 tensor predicting bounding boxes and class probabilities.
- Bounding box parameters $(x, y, w, h)$ and confidences are normalized to $[0, 1]$.
- Activation Functions:
All layers use Leaky ReLU:
\[f(x) = \begin{cases} x & \text{if } x > 0 \\ 0.1x & \text{otherwise} \end{cases}\]Final layer uses a linear activation.
Loss Function: A custom multi-part sum-squared error loss:
Penalizes:
- Bounding box coordinates (only if the box is responsible)
- Confidence scores (with different weights for object vs. non-object boxes)
- Classification error (only if object is present)
Key weights:
λ_coord = 5: Emphasizes accurate box localization.λ_noobj = 0.5: De-emphasizes confidence loss for cells without objects.
Predicts √width and √height to reduce sensitivity to large box errors.
Formula: \(\begin{aligned} &\lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}^{\text{obj}}_{ij} \left[(x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2\right] \\ &+ \lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}^{\text{obj}}_{ij} \left[(\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2\right] \\ &+ \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}^{\text{obj}}_{ij} (C_i - \hat{C}_i)^2 \\ &+ \lambda_{\text{noobj}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}^{\text{noobj}}_{ij} (C_i - \hat{C}_i)^2 \\ &+ \sum_{i=0}^{S^2} \mathbb{1}^{\text{obj}}_i \sum_{c \in \text{classes}} (p_i(c) - \hat{p}_i(c))^2 \end{aligned}\)
- Training Strategy:
135 epochs on PASCAL VOC 2007+2012 train+val sets.
Batch size: 64, momentum: 0.9, weight decay: 0.0005.
- Learning rate schedule:
- Warm-up from $10^{-3}$ to $10^{-2}$ in the first few epochs.
- $10^{-2}$ for 75 epochs → $10^{-3}$ for 30 → $10^{-4}$ for final 30.
- Regularization:
- Dropout (0.5 rate) after first fully connected layer.
- Data augmentation: random scaling and translations (up to 20%), and HSV exposure/saturation changes (up to 1.5×).
Limitations
YOLO has limitations due to strong spatial constraints—each grid cell predicts only two boxes and one class, limiting detection of nearby or grouped small objects. It struggles to generalize to unusual object shapes and uses coarse features from multiple downsampling layers. Its loss function treats errors in small and large boxes equally, though small errors in small boxes impact IOU more. Overall, the main error source is inaccurate localization.