
YOLO, You Only Look Once
Résumé
Nous présentons YOLO, une nouvelle approche de la détection d’objets. Les travaux antérieurs réutilisent des classifieurs pour la détection. Nous formulons plutôt la détection comme un problème de régression : boîtes englobantes et probabilités de classe en une seule évaluation. Un seul réseau prédit boîtes et classes directement à partir de l’image entière. Comme tout le pipeline est un seul réseau, il peut être optimisé de bout en bout.
L’architecture est très rapide : le modèle YOLO de base tourne en temps réel à 45 images/s. Une version plus petite, Fast YOLO, atteint 155 images/s tout en dépassant le mAP des autres détecteurs temps réel. Par rapport aux systèmes de pointe, YOLO fait plus d’erreurs de localisation mais moins de faux positifs sur le fond. Enfin, YOLO apprend des représentations très générales et surpasse d’autres méthodes (DPM, R-CNN) lors du transfert vers d’autres domaines (ex. œuvres d’art).
- Article original : You Only Look Once: Unified, Real-Time Object Detection
- Dépôt GitHub : Deep Learning Classics: Read, Review, Recode
Contexte et problématique
L’humain voit une image et sait immédiatement quels objets sont présents, où ils sont et comment ils interagissent.
Les systèmes de détection classiques adaptent des classifieurs (fenêtre glissante type DPM, ou propositions de régions type R-CNN puis classement). Un post-traitement affine les boîtes et les scores.
Ces pipelines sont lents et difficiles à optimiser car chaque composant est entraîné séparément.
YOLO reformule la détection en une seule régression : des pixels aux coordonnées des boîtes et aux probabilités de classe (you only look once). Un seul CNN prédit plusieurs boîtes et leurs probabilités. Avantages : YOLO est très rapide (45 fps), raisonne globalement sur l’image et apprend des représentations généralisables.
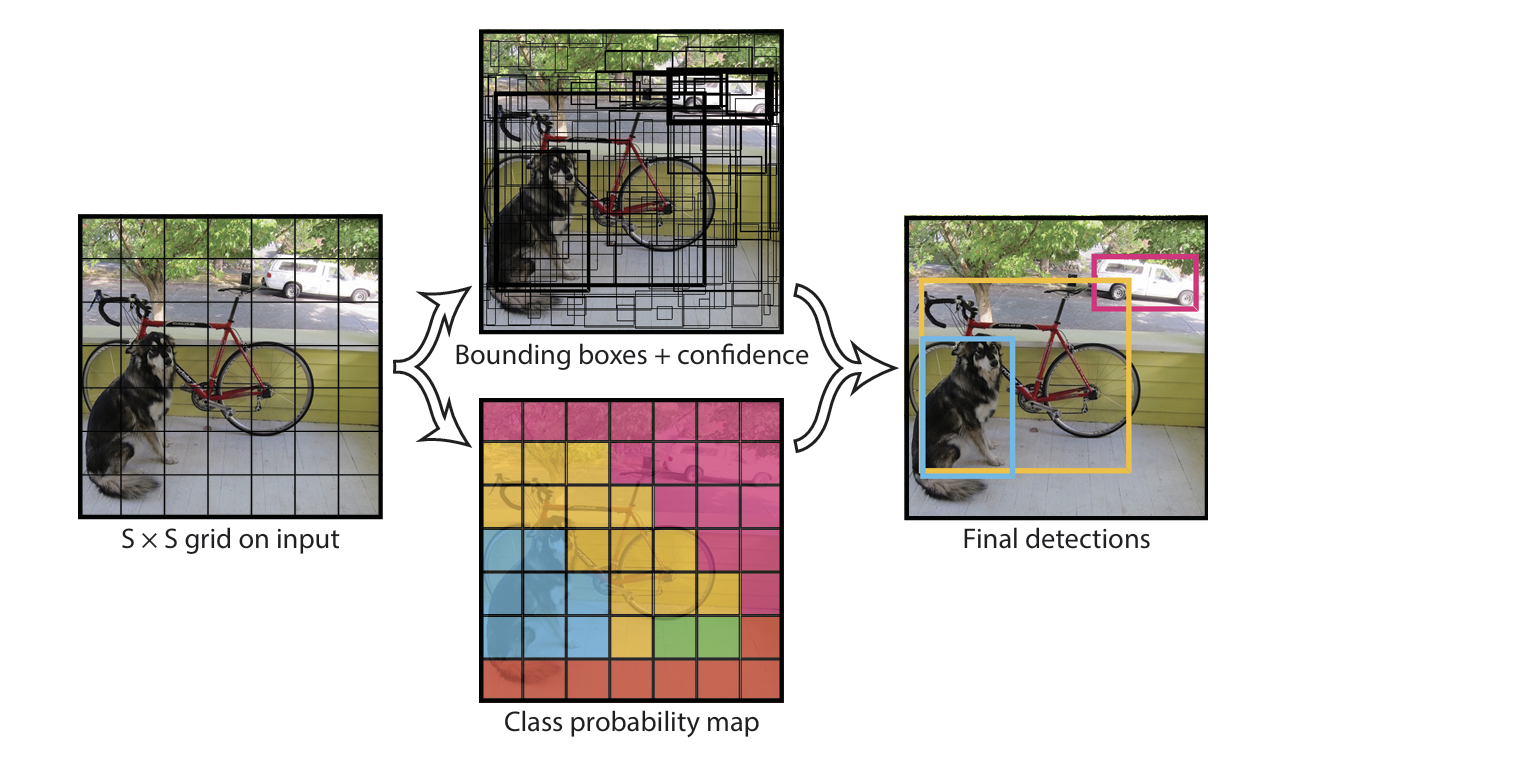
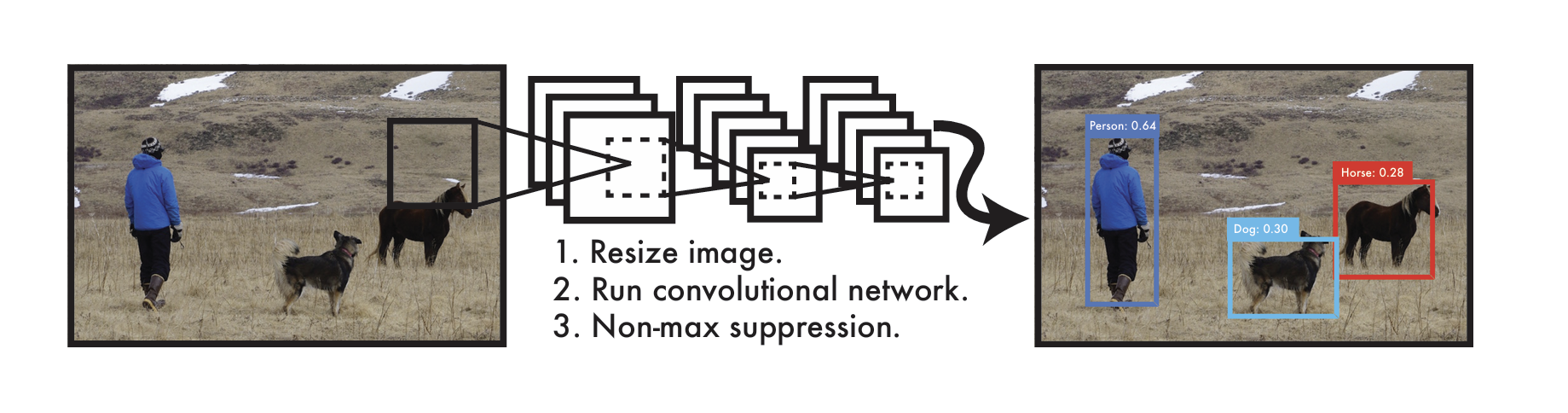 Système de détection YOLO.
Système de détection YOLO.
Idée centrale : détection unifiée
YOLO divise l’image en une grille $S \times S$. Si le centre d’un objet tombe dans une cellule, cette cellule est responsable de le détecter.
Chaque cellule prédit :
- $B$ boîtes, chacune avec :
- Coordonnées : $(x, y, w, h)$
- Score de confiance : \(\text{Confiance} = \Pr(\text{Objet}) \times \text{IOU}_{\text{vérité, prédit}}\)
- $C$ probabilités de classe conditionnelles sachant qu’un objet est présent : \(\Pr(\text{Classe}_i \mid \text{Objet})\)
Chaque boîte fait donc 5 prédictions : $(x, y, w, h, \text{Confiance})$.
Au test, le score de confiance par classe pour chaque boîte est : \(\Pr(\text{Classe}_i) \times \text{IOU}_{\text{vérité, prédit}} = \Pr(\text{Classe}_i \mid \text{Objet}) \times \Pr(\text{Objet}) \times \text{IOU}_{\text{vérité, prédit}}\)
Ce score combine la probabilité de la classe et l’adéquation de la boîte à la vérité terrain.
Le modèle. Les prédictions sont encodées en un tenseur S×S×(B×5+C).
Conception du réseau
YOLO est un CNN évalué sur PASCAL VOC : 24 couches convolutives pour les traits, 2 couches fully connected pour les boîtes et les classes. Inspiré de GoogLeNet avec des réductions 1×1 puis convolutions 3×3. Fast YOLO : 9 couches et moins de filtres, au détriment de la précision. Sortie : tenseur 7×7×30.
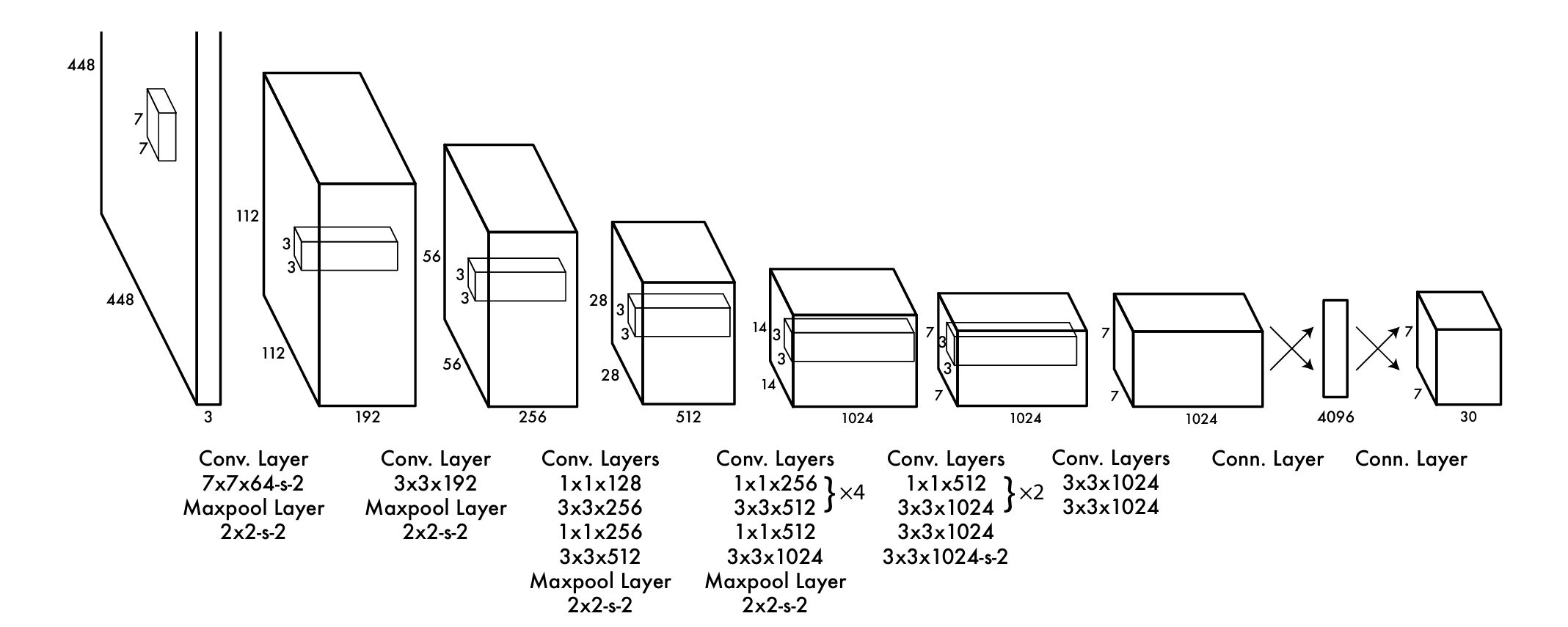 Architecture YOLO
Architecture YOLO
Entraînement
- Pré-entraînement : 20 premières couches convolutives sur ImageNet (1000 classes) avec Darknet, ~88 % top-5 sur la validation ImageNet 2012.
- Passage à la détection : 4 couches conv + 2 FC (initialisées aléatoirement). Résolution d’entrée 224×224 → 448×448.
- Sortie : tenseur 7×7×30 ; $(x, y, w, h)$ et confiances normalisés dans $[0, 1]$.
- Activations : Leaky ReLU partout, activation linéaire en sortie.
- Fonction de perte : erreur quadratique multi-parties (coordonnées, confiance objet/non-objet, classification). $\lambda_{\text{coord}} = 5$, $\lambda_{\text{noobj}} = 0.5$. Prédiction de $\sqrt{w}$ et $\sqrt{h}$ pour limiter la sensibilité aux grandes boîtes.
- Stratégie : 135 epochs sur PASCAL VOC 2007+2012, batch 64, momentum 0.9, weight decay 0.0005. LR : warm-up puis $10^{-2}$ (75 ep.) → $10^{-3}$ (30) → $10^{-4}$ (30). Dropout 0.5 après la première FC ; augmentation (scale, translation, HSV).
Limites
YOLO est limité par des contraintes spatiales fortes : chaque cellule ne prédit que deux boîtes et une classe, ce qui gêne la détection d’objets proches ou de petits objets groupés. Il généralise mal à des formes inhabituelles et utilise des traits assez grossiers. La perte traite de la même façon les erreurs sur petites et grandes boîtes, alors que les petites erreurs sur petites boîtes impactent plus l’IOU. La principale source d’erreur reste la localisation imprécise.